Anna Gienger
SEO Strategin | netzstrategen
Wir machen Dich und Deine Website fit für 2021. Unsere SEO-Workout-Serie startet mit einem Aufwärmtraining. Wie bei einem regulären Workout für den Körper, braucht Deine Website ein leichtes Warmup um gut vorbereitet in das eigentliche Training zu starten. Schritt 1 auf dem Weg zur fitten Website sind Crawling und Indexierung. Wir legen los!
Was bringt Dir das Warmup?
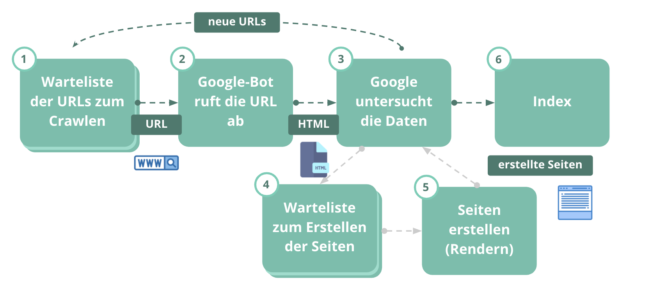
Was eine Suchmaschine nicht lesen kann, kann sie nicht verstehen. Und was sie nicht verstehen kann, zeigt sie nicht an. Crawling bezeichnet den Vorgang, dass Google alle Websiteninhalte durchsucht und permanent analysiert. Die Analyse der Website ist die Grundvoraussetzung, dass Inhalte bei einer Suchanfrage überhaupt gefunden werden können. Für uns ist die Steuerung des Crawlings und der Indexierung also die absolute Basis der Suchmaschinenoptimierung. Ohne Crawling und Indexierung keine Rankings. Ohne Warmup kein Training.
Was brauchst Du dafür?
Über die robots.txt kannst Du das Crawling steuern und einzelne Seitenbereiche vom Crawling ausschließen. Der Googlebot hat nur eine beschränkte Ausdauer, da er tagtäglich eine lange Strecke an Verlinkungen zurücklegen muss, um sich alle Inhalte anzusehen. Deshalb sollten wir Seitenbereiche, die nicht relevant sind, vom Crawling ausschließen, um so Kraft (= Crawlingbudget) zu sparen. Über die Steuerung der Indexierung stellen wir sicher, dass eine unpassende oder unwichtige Seite nicht für den Nutzer bei einer Suchanfrage ausgegeben wird. Ein bisschen so, wie wenn man sich beim Training regelmäßig die Hose hochziehen muss, damit keine unerwünschten Dinge im Blickfeld der anderen landen.So geht’s
ROBOTS NOINDEX
So heißt die HTML-Anweisung, die im Head-Bereich der Website stehen muss. Mit dieser Anweisung wird den Suchmaschinen-Bots gesagt, dass diese Unterseite nicht im Index landen soll. Dabei ist es egal, ob diese Seite von intern oder extern verlinkt wird. So sieht das Code-Snippet für deinen HTML-Befehl aus, den du auf der Website in deinem Head-Bereich hinzufügst:
<meta name="robots" content="noindex"/>

Wenn Du mit WordPress arbeitest, lädst Du dir am besten das Yoast PlugIn herunter. Dort kannst du für jede Seite angeben, ob sie im Index erscheinen soll oder nicht – und das ohne Code-Schnipsel.
Der hauptsächliche Verwendungszweck dafür ist der Ausschluss von Seiten, die keinen Mehrwert für den Nutzer haben: das Impressum etwa oder Fehlerseiten, wie die „404-Seite“, die auf fast allen Websites zu finden ist. Eine weitere wichtige Funktion ist, zu verhindern, dass Seiten auftauchen, die der Nutzer nicht sehen soll, wie beispielsweise die Log-in-Seite für Admins oder die Bilder der letzten Weihnachtsfeier.
ROBOTS.TXT DISALLOW
Mit dieser Anweisung in der robots.txt gibst Du einem Bot die Anweisung „Crawle diese Seite nicht“. So kannst Du das erwähnte Crawling-Budget steuern und auf die wichtigen Seiten lenken. Seiten, die so ausgeschlossen werden verbrauchen das Crawl-Budget nicht, da der Bot sie gar nicht erst ansteuert.
Die Angabe für deine robots.txt sieht wie folgt aus:
User-agent: *
Disallow: /platzhalter/
Die Angabe des User-Agents in Verbindung mit dem Stern bedeutet, dass die folgende Anweisung für alle Crawler gilt. Der Anweisung Disallow folgt die URL oder die Verzeichnisangabe, die nicht gecrawlt werden soll.
Aber Achtung, diese Seiten können trotzdem im Index landen und bei Google gefunden werden, wenn Google auf anderem Wege über diese gesperrte Seite stolpert.
Idealerweise setzt Du das daher immer in Kombination mit „noindex“ ein. So stellst Du sicher, dass eine unpassende oder unwichtige Seite wirklich nicht für den Nutzer bei einer Suchanfrage ausgegeben wird. Andernfalls kann es sein, dass diese unwichtige Seite noch einen externen Link von einer anderen Website erhält. Durch diesen Link könnte der Crawler die Seite immer noch finden und die URL indexieren.
Hierbei auch bitte die richtige Reihenfolge einhalten: erst auf noindex setzen, dann in der robots.txt vom Crawling ausschließen. Sonst verhindert der Parameter disallow dass Google auf der Seite selbst einen noindex-Parameter finden kann. Logisch, oder?
Geschafft!
Das Warmup ist geschafft. Nächste Woche geht weiter mit einem Ausdauer-Workout, das es in sich hat. In diesem Workout kümmern wir uns um den Body Deiner Website und um die wichtigsten Hygienefaktoren von Google.
Wenn Du in der Zwischenzeit noch mehr trainieren möchtest, kannst Du dir unser SEO Glossar kostenlos herunterladen. Mit diesem Spickzickel hast du alle Fachbegriffe auf einen Blick und jederzeit griffbereit.
netzstrategen SEO Audit: Deine Website unter der Lupe
Wir schauen Deine Website aus verschiedenen Richtungen an: inhaltlich und technisch. Dafür nutzen wir starke Tools, die uns bei der Fehlersuche helfen: Google Analytics, Google Search Console, Ryte und Sistrix.
Die Ergebnisse unserer Analyse zeigen und erklären wir Dir in einem gemeinsamen Workshop, bei dem wir Dich außerdem für Deine weitere Arbeit mit SEO fit machen.